Introduction to Neural Networks
Copyright © 1997 Simon Dennis
- What is a Neural Network?
- Architectures
- How a Neural Network Computes
- How a Neural Network Learns
- References
- Slides
What is a Neural Network?
The rapidly developing field of artificial neural networks emphasizes
biologically inspired approaches to problem solving.
Artificial neural networks process information differently from
traditional computers. Computation occurs in parallel across large
numbers of simple processing units, rather than in the serial
fashion of traditional computer architectures. Similarly, information
is distributed across the entire network rather than being located in
one specific place or address. In fact, neural computation is sometimes
called parallel distributed processing to emphasize how it
differs from traditional computing. In addition, simple learning
algorithms can be defined which alter the connections between units
(and therefore processing) as a result of experience. As we shall see
in the remainder of this workbook, these properties have direct
consequences for the way one thinks
about computation, cognition and the mind. As a consequence, artificial
neural networks enjoy multidisciplinary appeal.
For computer scientists and engineers, neural
networks provide a paradigm for solving problems which is often very
successful particularly in domains that are poorly understood or
subject to uncertainty. For linguists, cognitive scientists,
psychologists and philosophers, neural networks provide a metaphor for
the way in which cognitive processes such as perception, attention,
learning, memory, language, reasoning and thinking occur. And for
neuroscientists the mathematical simplification of the physiological
processes allows for the analysis of large networks of units and provides
insight into how the myriad interactions of neurons result in overt
behaviour.
In the human brain, there are approximately 10 billion
neurons, each of which is connected to about 10,000 other neurons. A single
neuron (Figure 1) consists of a cell body called the soma, a number
of spine-like extensions called dendrites, and a single nerve fibre
called an axon which branches out from the soma and connects to other
neurons. Neurons combine input signals from these connections
or synapses to determine if and when it will transmit a signal to
other neurons through the connecting dendrites and synapses.
The synapses modulate the input
signals before they are combined, and the system learns by changing
the modulation at each synapse. Neurons inter-connected by axons and
dendrites form the basic neural network.
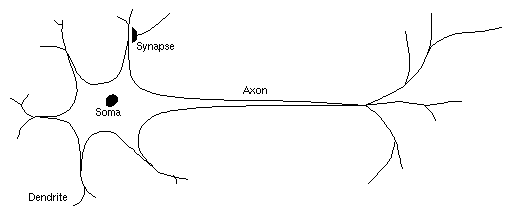
Figure 1: A schematic of a typical neuron.
Figure 2 shows an artificial neural network in the BrainWave simulator. The
squares are units, which represent a mathematical simplification
of biological neurons. The overall level of activity of a unit is
called its activation, which is represented by the size and colour of
the squares (red being positive and blue being negative). The arrows
connecting the units are weights, which represent the synapses.
Weights can either be excitatory (red) or inhibitory (blue). Units
connected to active units by excitatory weights will become more active,
while units connected to active units by inhibitory weights will become
less active.
Figure 2: The Jets and Sharks Network (McClelland, 1981)
To see a neural network in operation click on the "Art" unit. It should turn red indicating
that it is now active. Then click on thethe
"Cycle" button. Notice how the activations of the units alter as a function of
the activations of the units to which they are connected.
Architectures
Artificial neural networks (and real neural networks for that matter)
come in many different shapes and sizes (see Figure 3). In feedforward
architectures, the activations of the input units are set and then
propagated through the network until the values of the output units
are determined. The network acts as a vector-valued function taking one
vector on the input and returning another vector on the output. For
instance, the input vector might represent the characteristics of a
bank customer and the output might be a prediction of whether that
customer is likely to default on a loan. Or the inputs might represent
the characteristics of a gang member and the output might be a
prediction of the gang to which that person belongs.
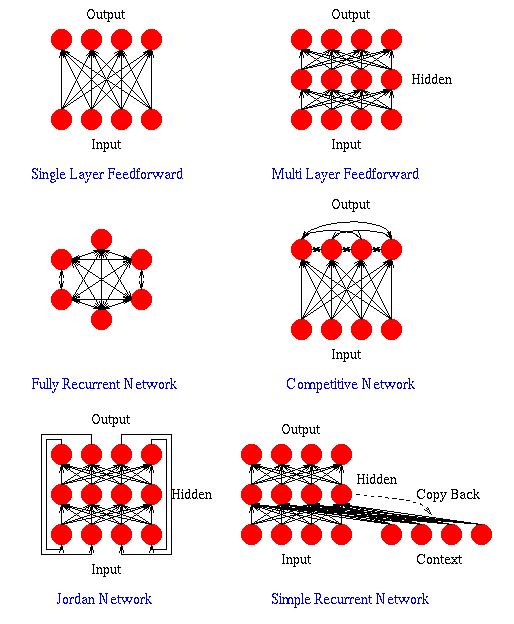
Figure 3: Some artificial neural network connection structures.
Feedforward networks may have a single layer of weights, where the
inputs are directly connected to the outputs, or multiple layers with
intervening sets of hidden units (see Figure 3). Neural networks use
hidden units to create internal representations of the input patterns.
In fact, it has been shown that given enough hidden units it is
possible to approximate arbitrarily closely almost any function with
a simple feedfoward network. This result has encouraged people to use
neural networks to solve many kinds of problems.
The competitive network is similar to a single-layered feedforward
network except that there are connections, usually negative, between
the output nodes. Because of these connections the output nodes tend
to compete to represent the current input pattern. Sometimes the output
layer is completely connected and sometimes the connections are
restricted to units that are close to each other (in some
neighbourhood). With the appropriate learning algorithm the latter sort
of network can be made to organize itself topologically. In a topological
map, neurons near each other represent similar input patterns. Networks
of this kind have been used to explain the formation of topological maps
that occurs in many animal sensory systems including vision, audition,
touch and smell (see Chapter Four for an example of a competitive network
that develops topological maps).
The fully-recurrent network (see Figure 3) is perhaps the simplest of
neural network architectures. All units are connected to all other
units and every unit is both an input and an output. Typically, a set
of patterns is instantiated on all of the units one at a time. As
each pattern is instantiated the weights are modified. When a degraded
version of one of the patterns is presented, the network attempts to
reconstruct the pattern.
Recurrent networks are also useful in that they allow networks to
process sequential information. Processing in recurrent networks
depends on the state of the network at the last timestep.
Consequently, the response to the current input depends on previous
inputs. Figure 3 shows two such networks: the simple recurrent network
and the Jordan network.
Having taken a birds eye view of the different sorts of connection structures
that have been used in artifical neural networks, we will now zoom
in on a single unit and discuss the processing that occurs there.
How a Neural Network Computes
Associated with each unit is a transfer function which
determines how that unit's value (or activation) is updated.
Typically, the transfer function multiplies each weight projecting
to the unit by the activations of the (input) units which the
weights project from. The sum of the weight inputs is added to a
baseline or bias value to calculate the net input
to the unit. Then a very simple activation function is applied
to the net input (see Figure 4).
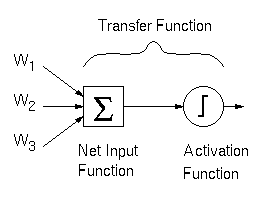
Figure 4: The Transfer Function
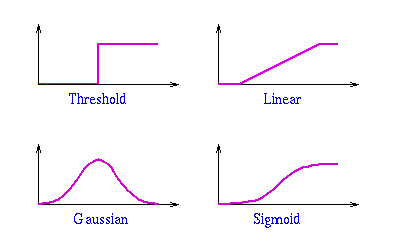
Figure 5: Some common activation functions.
Figure 5 shows some of the most common activation functions. In each
case, the x-axis is the value of the net input and the y-axis is the
output from the unit. To see how a neural network computes a function,
consider the following network, which is designed to implement the
logical function AND.
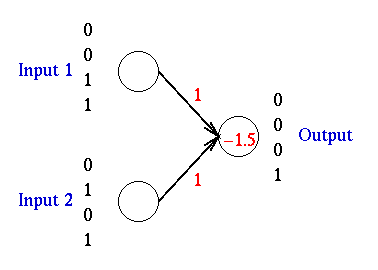
Figure 6: AND Network.
The AND network has two input units and a single output unit. The
output unit employs a threshold activation function. If its net
input is greater than zero the units activation will be one; if
the net input is less than zero the unit's activation will be zero.
Both weights are set to 1 and the bias is set to -1.5.
The AND function is represented by the numbers next to the units where
each number represents a possible input. There are four possible
combinations: 00, 01, 10, and 11. When both input units are 0 the
output should be 0, when either unit one or unit two is zero the
output should be zero, but when both inputs are 1 the output should
be 1.
Consider the case where both inputs are zero. The net input is:
net input = 0x1 + 0x1 - 1.5 = -1.5
which is less than the threshold of zero, so the activation of the output
unit will be 0. When unit 1 is set to 1 and unit 2 is set to 0 the net
input is:
net input = 1x1 + 0x1 - 1.5 = -0.5
Similarly, if the unit 2 is set to one and unit 1 is set to zero net input is:
net input = 0x1 + 1x1 - 1.5 = -0.5
In both of these cases, the net input is less than threshold of zero, so
the output of the network is 0. However, when both unit 1 and unit 2 are
set to 1, the net input is:
net input = 1x1 + 1x1 - 1.5 = 0.5,
which is greater than the threshold, and the output of the network is 1.
Given these weights the network implements the logical AND function.
Exercise 1: Alter the weights of the network to implement the
logical OR function (see following table).
| The OR Function
|
|---|
| Unit 1 | Unit 2 | Output Unit
|
|---|
| 0 | 0 | 0
|
| 1 | 0 | 1
|
| 0 | 1 | 1
|
| 1 | 1 | 1
|
Exercise 2: Alter the weights of the network to implement the logical
XOR function (see following table).
| The XOR Function
|
|---|
| Unit 1 | Unit 2 | Output Unit
|
|---|
| 0 | 0 | 0
|
| 1 | 0 | 1
|
| 0 | 1 | 1
|
| 1 | 1 | 0
|
Now lets consider a larger example. Suppose we want develop a network
to recognize the letters "I", "L", and "T". Firstly, we need to choose
a input representation. Figure 7 shows one possible artificial "retina".
The units are arranged in a three by three grid. An active unit (=1)
represents the foreground colour, while an inactive unit represents the
background colour.
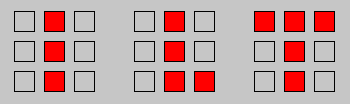
Figure 7: ILT Input Representations.
The task is to identify each of these letters. So we will have three output
units representing "I", "L", and "T" respectively. The "I" unit should be
active when the "I" pattern is presented and should be inactive when either the "L",
or the "T" patterns are presented. Similarly, the "L" and "T" units should be
active only when the corresponding pattern is presented.
To recognize the "T" we can connect the units that will be active in the "T"
input pattern to the "T" output unit with weights of positive 1 and then
set the bias to 4.5 (see Figure 8). When the "T" is presented the net input will be 5 which
will exceed the bias and the "T" unit will active. Note that neither
of the other two letters have 5 active units and hence they will never be able
to create a netinput over 4.5 that will activate the "T" unit.
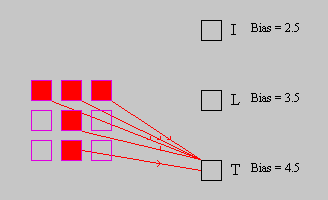
Figure 8: T Weights.
To recognize the "L" we can connect the active units to the "L" output unit
and set the bias to 3.5 (see Figure 9). When the "L" input pattern is present
the netinput will be 4 which will exceed the bias and activate the "L" output
unit. Note that the "I" and "T" patterns only overlap on three units, so the
netinput generated by these two letters will only be 3 which is below the bias.
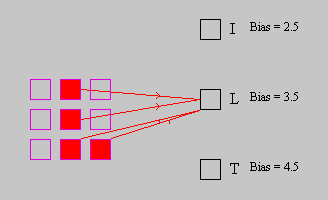
Figure 9: L Weights.
The "I" pattern is somewhat more difficult. Because the "I" input
representation is a subset of the "L" and "T" patterns we cannot just use bias
to ensure that the "I" output unit does not become active when "L" or "T"
are presented. Instead we connect negative weights from the units that are
active in the "T" and "L" inputs but not in the "I" input. When these
patterns are presented the negative weights will decrease the netinput
taking it below the 2.5 bias (see Figure 10).
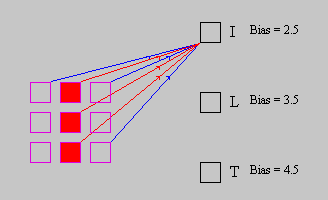
Figure 10: I Weights.
We have now successfully constructed a network to identify the letters
"I", "L" and "T". While it is possible in a simple example such as this to
select the weights by hand, it quickly becomes infeasible as the size of the
network and the number of patterns (c.f. letters) increases. In the next section,
we describe the main kinds of learning algorithms that have been developed to
automatically select weights.
How a Neural Network Learns
The output of a network, given its input, depends on the connection
structure and the weights. In general, the connection structure is held
constant and the weights are modified to allow the network to implement
different functions. How the weights are modified depends on the
objective of the network and the information available to the learning
rule. There are three main learning paradigms:
- Supervised Learning with a Teacher: The network is provided with a set of
inputs and the appropriate outputs for those inputs.
- Supervised Learning with Reinforcement: The network is provided with a
evaluation of its output given the input and alters the weights to try to
increase the reinforcement it receives.
- Unsupervised Learning: The network receives no external feedback but has
an internal criterion that it tries to fulfil given the inputs that it faces.
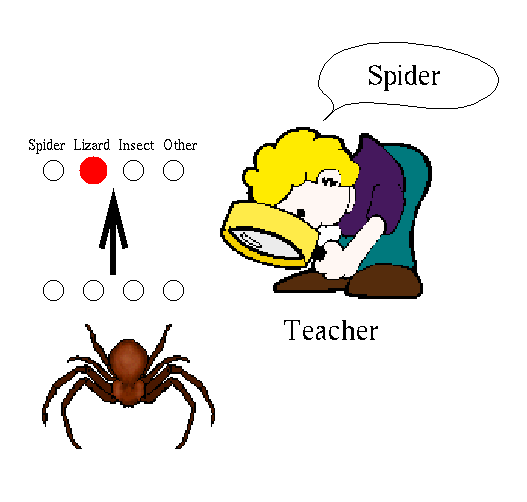
Figure 7: Supervised Learning with a Teacher
Figure 7 depicts supervised learning with a teacher. In this paradigm
the learning algorithm is given a set of input/output pattern pairs.
The weights are adjusted so that the network will produce the required
output in future. In the example of figure 7 the algorithm would be
given a set of pictures of animals that the teacher classifies as spider,
insect, lizard or other. If the network is shown a spider, but
classifies it as a lizard then the weights are adjusted to make the
network respond "spider".
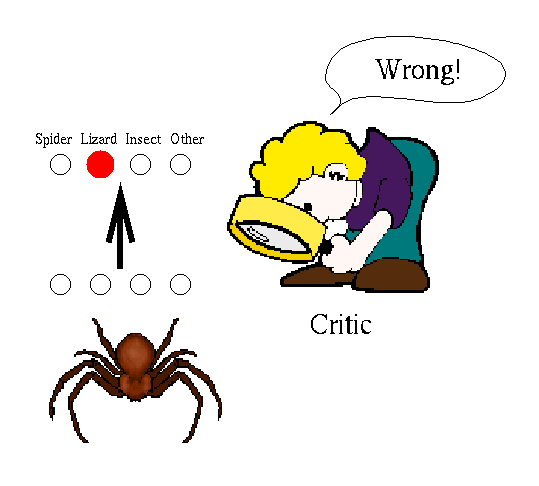
Figure 8: Supervised Learning with Reinforcement
Supervised learning with reinforcement (Figure 8, also known as
learning with a critic) is similar to learning with a teacher except
that instead of being told the appropriate output
given the input, the learning algorithm guesses at the right output and
is told if it is correct. The algorithm updates the weights to
maximize the number of inputs on which it is correct. In the example of
figure 8, the network is told that it is incorrect when it classifies
the spider as a lizard - but it isn't told what the correct
classification would be. For this reason, learning with a critic is
often more difficult and takes longer. Sometimes, however, we don't
know what the correct output given an input should be and learning with
a critic is the only learning that is possible. For instance, if
you were to construct a neural network to control a chemical plant and
you wanted to make sure that the temperature of the plant did not
exceed a certain bound, you may not know what settings of the valves
should be used at a given time. If, however, the temperature rises
above the bound you know that what the network just did wasn't good.
That is, you can supply critic information, but not teacher
information, so a reinforcement algorithm could be applied.
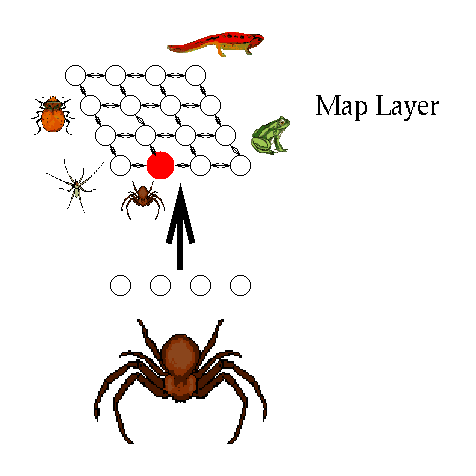
Figure 9: Unsupervised Learning
The final learning paradigm, depicted in Figure 9, is unsupervised
learning. Unsupervised learning does not receive information from
either a teacher or critic. Instead, it relies on an internal criterion
to guide learning. For instance, in Figure 9 the objective is to
create an output representation in which similar inputs activate output
units that are close to one another (i.e. forming a topological map,
see above). The network is shown a series of animals and gradually
changes the weights so that similar animals are mapped to adjacent
units. From an intial random assignment, the spiders end up in the
bottom left hand corner - near the insects, which are similar. The
lizards and frogs end up at the opposite extreme of the map (the top
right hand corner).
We have now considered the main types of learning paradigms. Within these
general structures there are many variations in exactly how the weights
are updated. In Connectionist Models of Cognition we will examine some
of the major algorithms. Now, however, it is time to get our hands dirty
running and constructing neural networks using the BrainWave simulator.