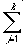 xajbj (2)
xajbj (2)
Memory Representations
Memory representations can include items, contexts or, combinations of
items and contexts (associations).
Matching and retrieval processes can also be used to access episodic memory representations or generalised representations.
Test instructions will determine which combinations of access procedures are used and what type of information is accessed. By combining different access procedures with different types of information, the Matrix Model is able to account for a wide array of memory tasks.
| Access Process | Process Output | Type of Task | |
|---|---|---|---|
| Episodic | Generalised | ||
| Matching | Scalar Quantity | Recognition | Familiarity Rating Lexical Decision |
| Retrieval | Response Vector | Cued Recall | Free Association Word Completion |
Words/concepts = A, B etc (uppercase letters, beginning of alphabet)
Context = X
Memory/Vector representations of words and context = a, b, x (lowercase letters)
Items are distinguished by subscripts (e.g. ai). A distractor item is indicated by a "d".
Vectors
Items and contexts are represented as vectors of feature elements.
These elements can assume binary values of either 0 or 1, where 1 is
indicative of a feature component and 0 specifies the absence of a
feature component. The number of elements in each vector and the
proportion of elements assigned a value of 1 are free parameters in the
Matrix Model. Although, the proportion of elements assuming a value of
1 will be limited, in order to create sparse representations.
Dot Products
One can measure the similarity of two
vectors by calculating the dot (scalar) product of the vectors. The
dot product is formed by multiplying a row vector by a column vector.
Example: Match (1 0 0 1) (1 0 0 1)T = (1 x 1 + 0 x 0 + 0 x 0 + 1 x 1) = 2 Example: No Match (1 0 0 1) (0 1 1 0)T = (1 x 0 + 0 x 1 + 0 x 1 + 1 x 0) = 0Matches can be performed to compare the similarity between study and test contexts, and the similarity between items encoded at study and test. Matching values are denoted by the following symbols:
c = similarity between the study and test context
s = similarity between the same word encoded at study and test
m = similarity between different words at study and test
>Matrix Products
While individual items and contexts
are represented as single vectors (a, b, x), associations between
items and contexts are represented by matrices derived from the matrix
product of these vectors. Matrix products are formed by multiplying
column vectors by row vectors. The resulting matrix product represents
the association (or binding) between either items, or item(s) and
context.
Example 1: 2-way association between a single item (A) and a
context (X) This binding is represented as a context-to-item
association (xa), where
x = n element column vector
a = n element row vector
The matrix product of this two-way association can be conceptualised as a square and is called a tensor of rank 2.
Example 2: List of items (A1, A2,...,Ak) and a context (X) Context and item vectors are multiplied, as above. The resulting context-to-item associations are then summed together in a linear combination and this sum represents the memory of the study list (E).
E = xa1 + xa2 + ... + xak (1)
Example 3: 3-way associations between a list of word pairs (A1B1, A2B2,...AkBk) and context (X). Each association is represented mathematically as a 3-dimensional array (xajbj), where
x = n element column vector
aj = n element row vector
bj = n element orthogonal vector
The matrix products of these associations can be conceptualised as cubes and are known as tensors of rank 3. Rank-3 tensors are produced by postmultiplying the matrix xaj by bj. Thus all of the elements in bj are multiplied with every element in xaj. The resulting associations are then summed together to form the memory for the list (E).
E = xajbj (2)
Pre-existing Memories
Because test performance can be influenced by both list memories and
pre-existing memories, list memories (E) are added to pre-existing
memories (S), also represented as a n x n matrix (e.g. using Example
3).
M = xajbj + S (3)
Recognition
Recognition involves a matching process, where the overall similarity
between the test cues (x and ai) and memory (M) is calculated.
Because this is an episodic task, the test cues involve both word cues
and a context cue (e.g., Did you study these words (Ai), in the list
that I showed you before (X) ?). This episodic matching process is
accomplished by combining the test cues into an associative matrix
(xai) and determining a strength value (dot product) between:
(a) the cue matrix (xai), and
(b) the memory matrix (M = xaj + S).
Example 1: Studied Test Word (Ai)
xai . M = xai . ( xaj + S)
= xai . xaj + xai . S
= (x . x) (ai . aj) + xai . S
= (x . x) (ai . ai ) + 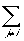 (x . x) (ai . aj) + xai . S
(x . x) (ai . aj) + xai . S
Inserting the expected matching value: E[xai.M] = c s + (k - 1) c m + g
where
c = similarity between the study and test context
s = similarity between the same word encoded at study and test
m = similarity between different words at study and test
g = contribution of pre-existing memories
Example 2 : Non studied Test Word (D)
xd . M = xd . ( xaj+ S) (5)
= xd . xaj + xd . S
= (x . x) (d . aj) + xd . S
where
E[xd.M] = c m k + g
Note that the matching operations in the above equations can be collapsed down into several components, including :
(a) a match between the test cue and the pre-experimental memories
(i.e., xai . S or xd . S), and
(b) a match between the test cue and the experimental memories
(i.e., xai . xaj or xd . xaj )
The match between the test cue and the experimental memories can further be collapsed down into :
(a) a match between the context on study and test occasions
(x . x = c), and
(b) a match between the study and test items
(ai . ai = s and ai . aj = m) or (d . aj = m)
Thus the final scalar-product derived from these equations, represents the match of the contexts on the study and test occasions (c) weighted by the match of the items on the study and test occasions (s and m). Consequently, memories that are conjointly defined by context and test cues will be weighted more heavily than items not studied in that context. This mechanism enables the model to avoid interference (large weights) from other items studied in the same context and also from previous contexts in which items have appeared.
Cued Recall with a List Associate
This episodic retreival task involves 3-way associations between a list
of word pairs (A1B1,
A2B2,...AkBk) and context
(X). Representations are stored in a rank-3 tensor at study. This is
formed by multiplying the matrix xaj by vector bj
(Refer back to Example 3).
M = xajbj + S
Subjects are then asked to recall list targets (bi) at test, using list associates (ai) and context (x) as cues. The retrieval cues (x and aj) are combined to form an associative matrix cue (xai). Retrieval then involves the pre-multiplication of the rank-3 tensor (M) by the retrieval cue (xai).
xai . M = xai . xajbj + S (6)
= [(xai)(xaj)] bj + xai . S
= [(x . x) (ai . aj)] bj + xai . S
= (x . x) (ai . ai)bi + (x . x) (ai . aj)bj + xai . S
Inserting the expected values:
E[xai . M] = c s bi + c m bj + g
The end product (matrix product) of this process will comprise a target vector of feature weights. This featural information can be used to produce a word or item reponse.
Note that the target vector is weighted by:
(a) the similarity of the context on the study and test occasions
( x . x = c), and
(b) the similarity of the list cue on the study and test occasions
(ai . ai = s) and (ai . aj = m)
Note also that the weights for the same associate (s) will be greater
than the weights for different associates (m). Also, pre-experimental
memories (S) are not given a context weight (c). Consequently, context
and list cues are able to converge on the appropriate associations.
These mechanisms allow the model to decrease interference from other
items learned in the same context and also from other pre-existing
associates of that cue.
Matrix Model Tutorial Questions
Complete the following questions by accessing the
Matrix Model simulator.
Humphreys, M.S., Bain, J.D., & Burt, J.S. (1989). Episodically unique and generalized memories: Applications to human and animal amnesics. In S. Lewandowsky, J.C. Dunn & K. Kirsner (Eds.) Implicit Memory: Theoretical Issues. (pp. 139-158). Erlbaum Associates: Hillsdale, N.J.
Humphreys, M.S., Bain, J.D., & Pike, R. (1989). Different ways to cue a coherent memory system: A theory for episodic, semantic and procedural tasks. Psychological Review, 96, 208-233.
Pike, R. (1984). A comparison of convolution and matrix distributed memory systems. Psychological Review, 91, 281-294.
Wiles, J., & Humphreys, M.S. (1993). Using artificial neural networks to model implicit and explicit memory. In P.Graf & M. Masson (Eds.) Implicit Memory: New Directions in Cognition, Development, and Neuropsychology. (pp. 141-166). Erlbaum: Hillsdale, New Jersey.
Note: the type of vector (i.e., row, column, orthogonal) can also be inferred from the order of the vector symbols, where: 1st vector = column vector; 2nd vector = row vector; and 3rd vector = orthogonal.